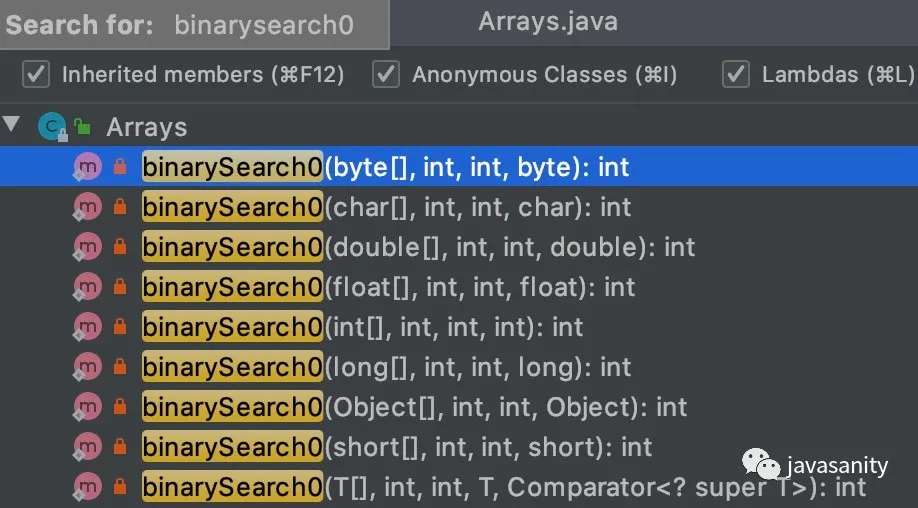
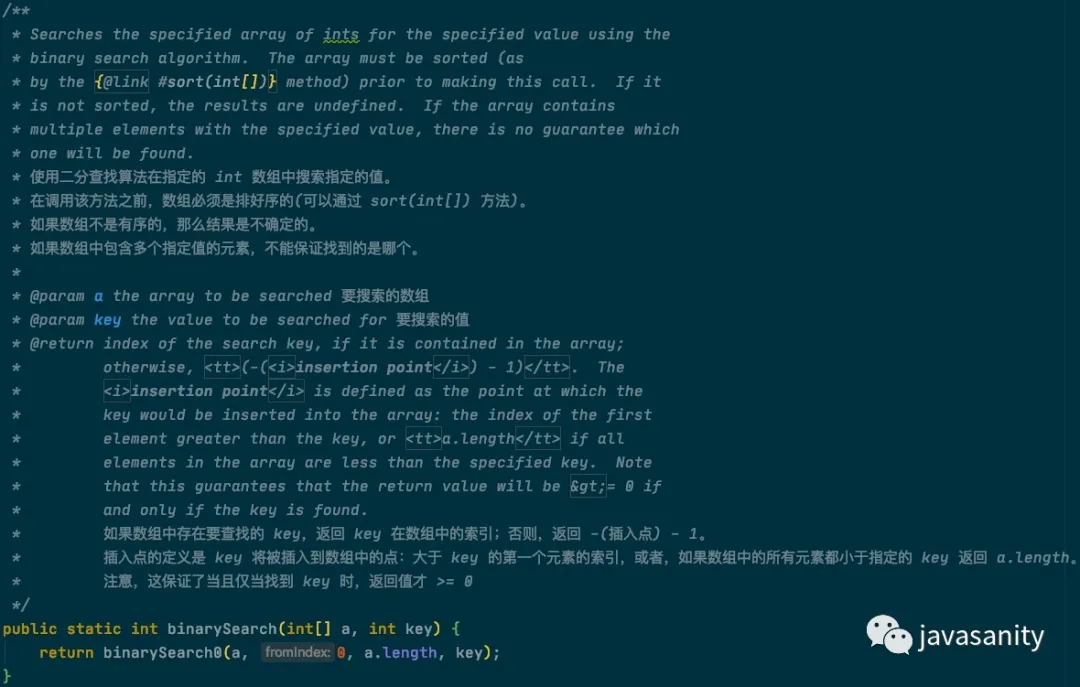
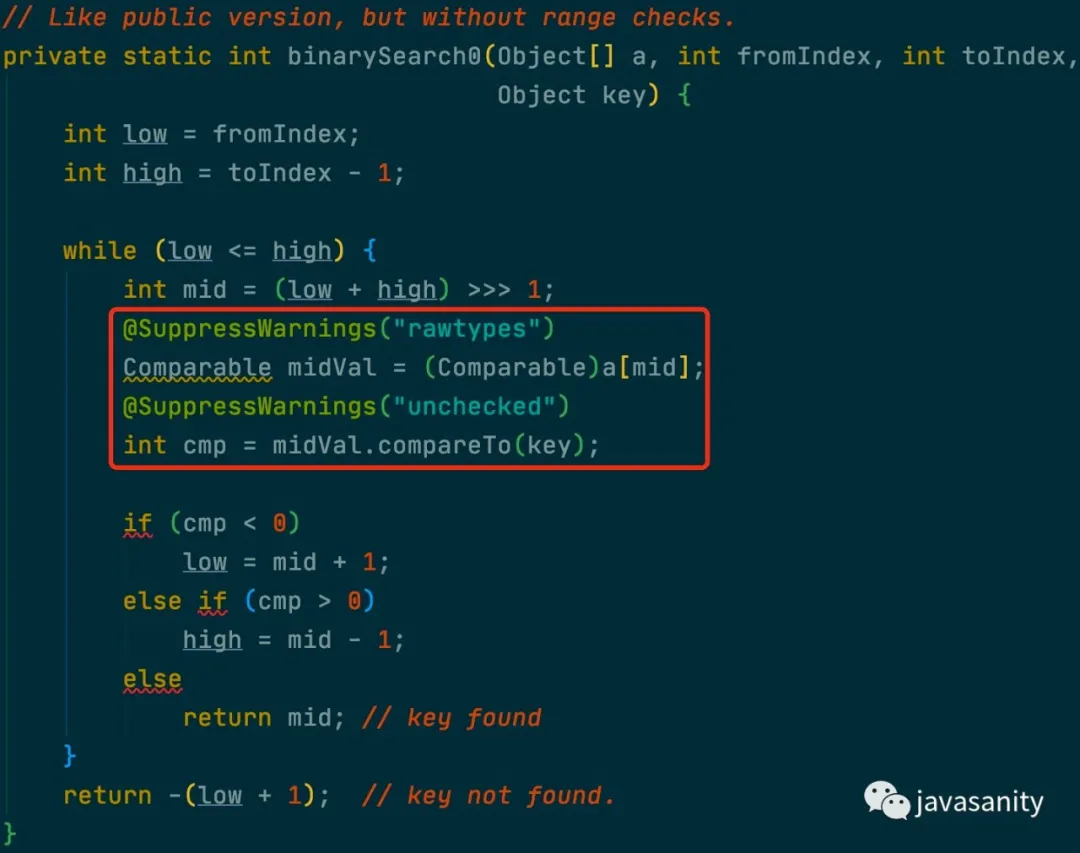
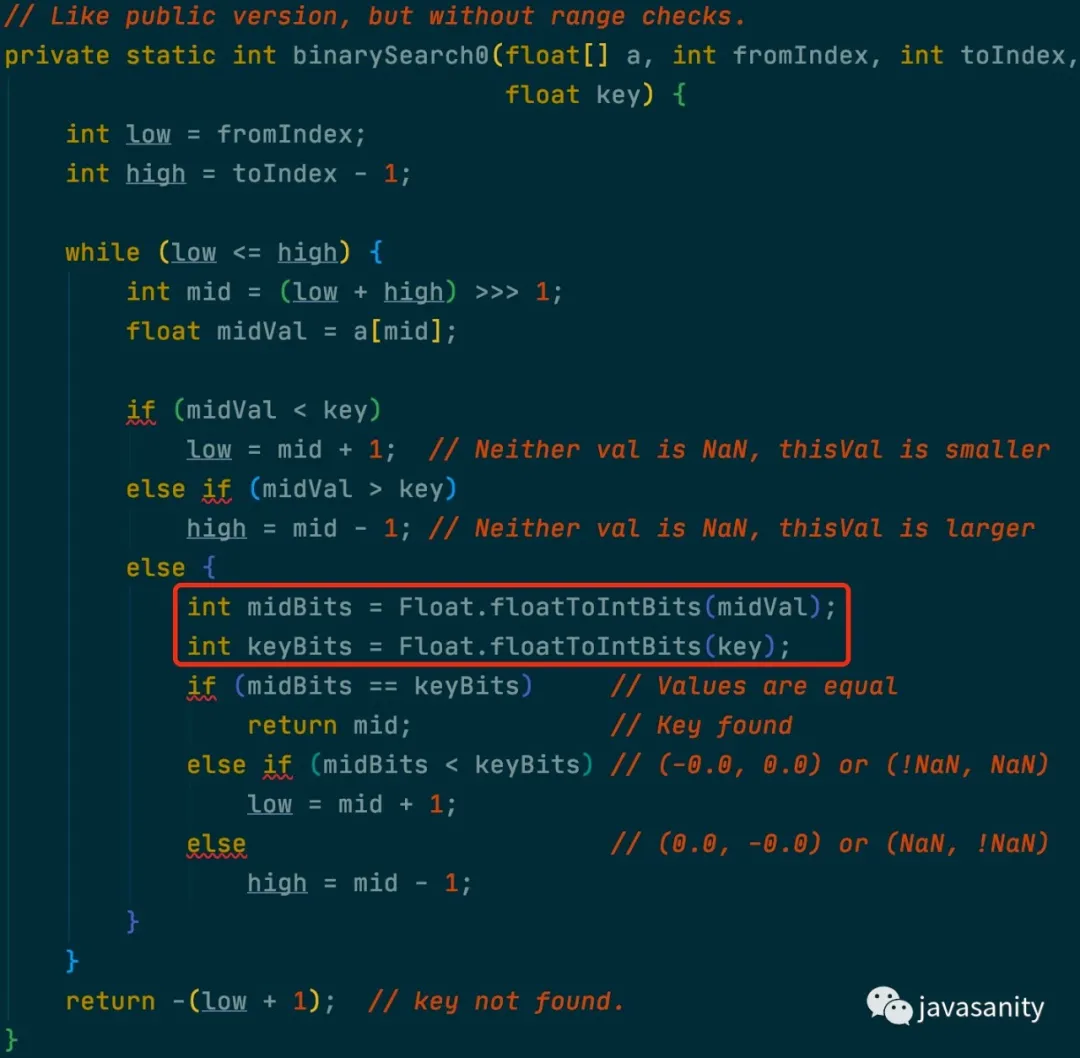
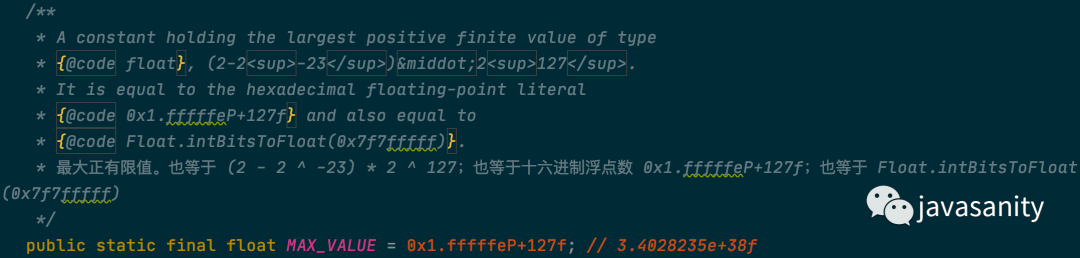
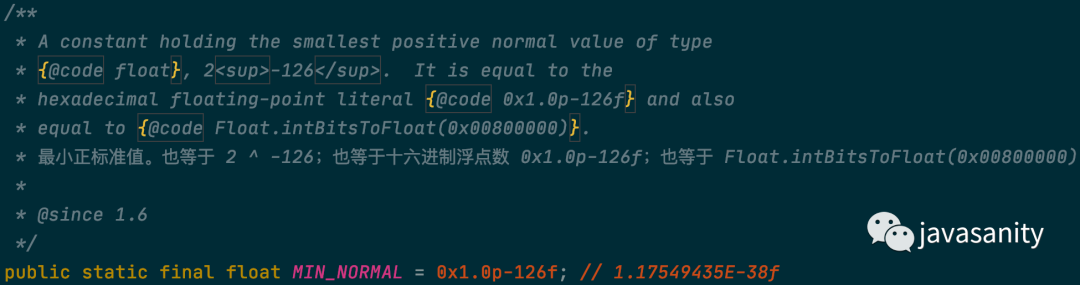
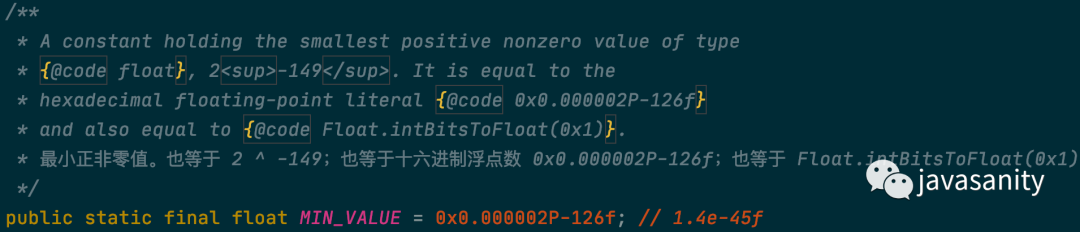
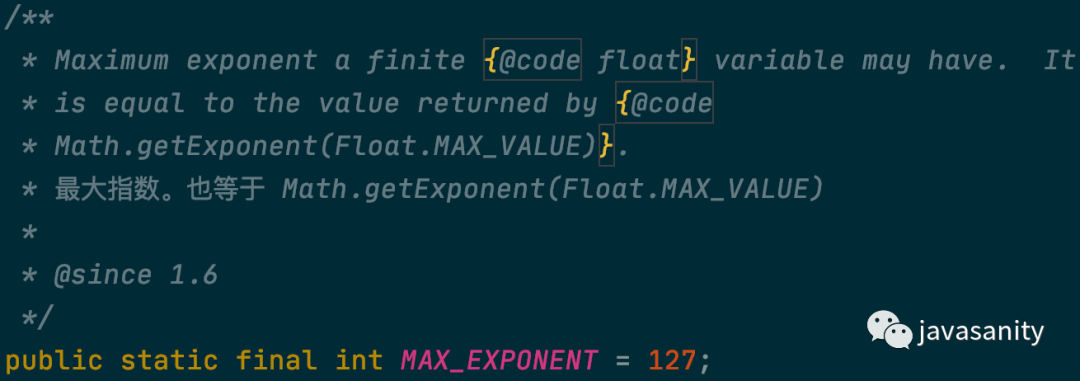
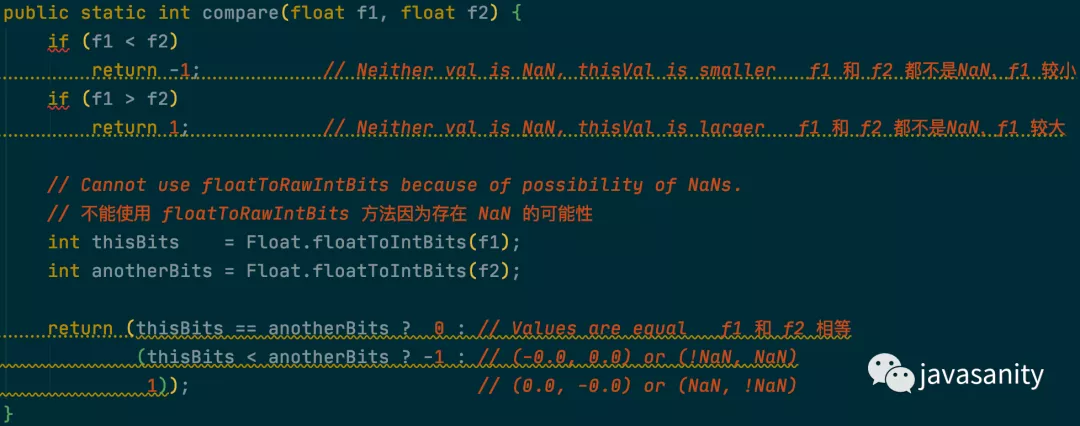
1
在计算机科学中,Trie 又称字典树或前缀树,顾名思义,它是一个树形结构。Trie 树通常专门用来处理字符串,解决在一组字符串集合中快速查找某个字符串的问题。
Trie 的典型应用就是自动补全、搜索提示等。例如命令行或 ide 的自动补全;例如在搜索引擎中输入一个关键字或网址,可以自动弹出可能的选择,而当没有完全匹配的搜索结果时,可以返回前缀最相似的可能结果。
利用 Trie 树可以做到:查询每个字符串的时间复杂度和字符串总数量无关,只和查询字符串的长度有关。
怎么做到的呢?
在实现上,Trie 是一棵多叉树。存储时,将每个字符串以字符为单位拆开存储在每个节点上,利用字符串之间的公共前缀,将重复的前缀合并在一起。结构如下图:
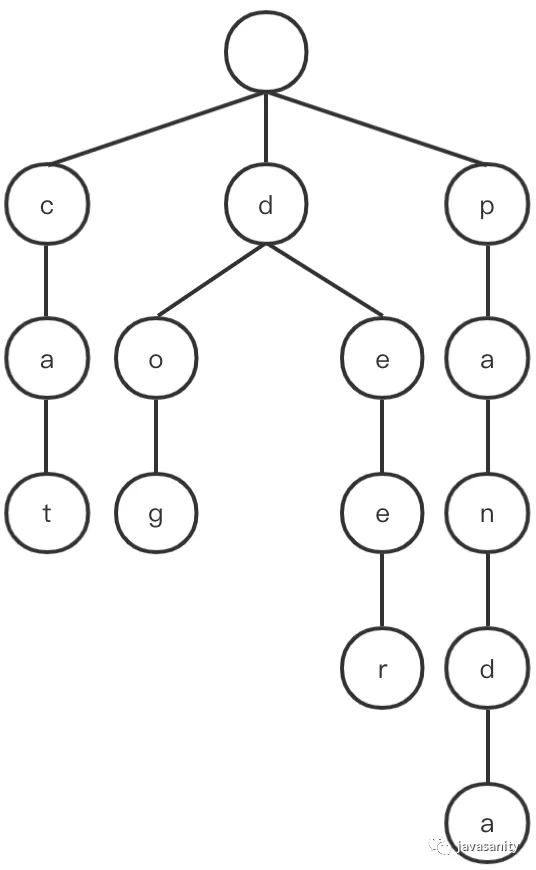
可以看到,在这棵树上,每个节点的所有子孙节点都有相同的前缀,而根节点是一个空节点,不包含任何信息。
这样,查找任何字符串,从根节点出发,最多需要查询字符串的长度即可找到相应的字符串。
定义节点
我们知道,英文字母表中一共有 26 个英文字母,所以相应地每个节点应该有 26 个指针指向下一个节点,所以在 Trie 中每个节点可以这样定义:
1 | class Node { |
但是,考虑到不同语言,不同情境,比如要存储的字符串要包含大小写,或包含数字,或要存储的字符串是网址,或邮件地址,甚至更加复杂的内容时,26 个指针是不够的。当然某些情况下,26 个指针又太富裕,会造成不必要的浪费。
这样看来,直接写死 26 并不太好,至少不够灵活,除非我们能非常确定我们的业务场景只需要有固定的 26 个指针。我们希望最好能够用动态的方式来解决这个问题,怎么做呢?我们可以用 Map<char, Node> 来作为 next 的实现。
1 | class Node { |
再仔细想想,当我们要在 Trie 中搜索某个字符串时,其实已经知道接下来要搜索的字符是什么了。所以更准确来讲,我们应该把字符标到 Trie 的边上,如下图:
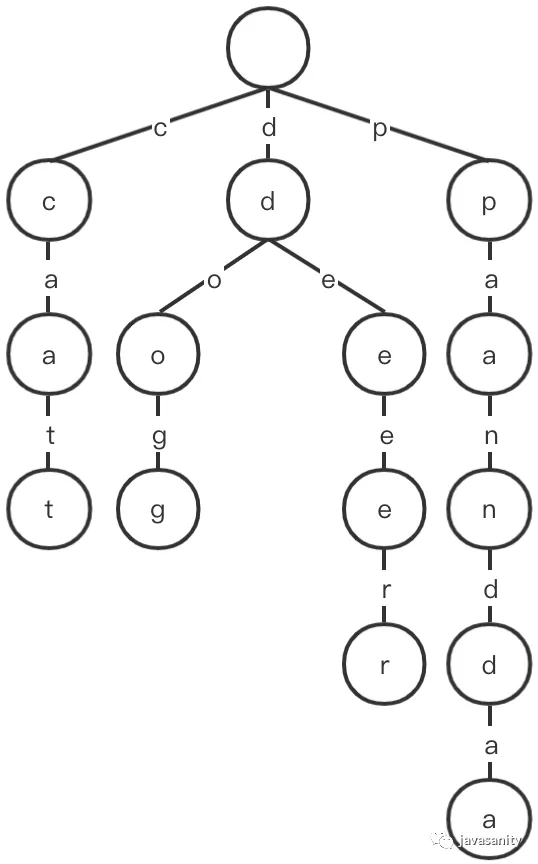
因此,在 Node 节点的实现中其实并不用保存这个字符的值。(当然,也得承认,某些情况下在节点中多存储一些信息可以帮助我们更快的组织某些逻辑)
1 | class Node { |
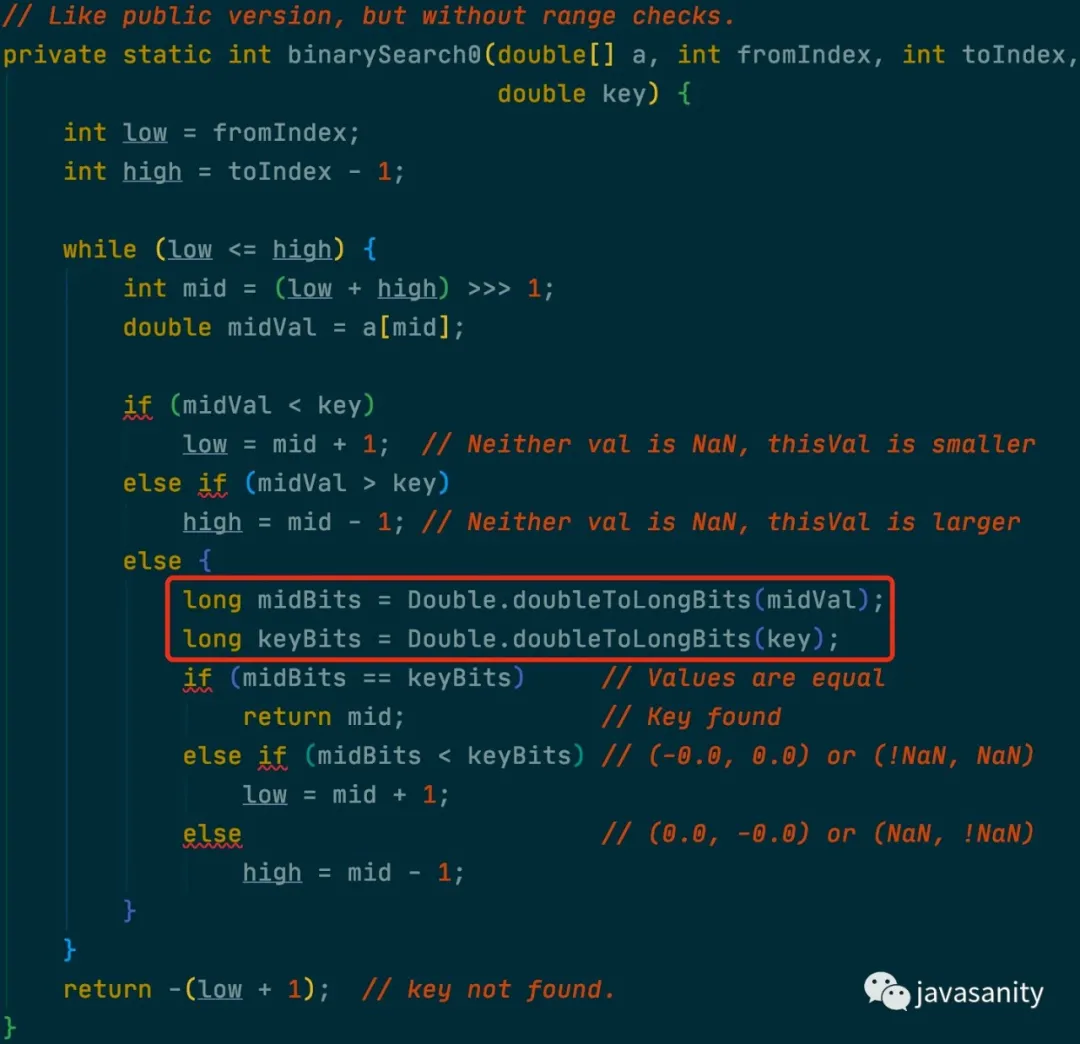
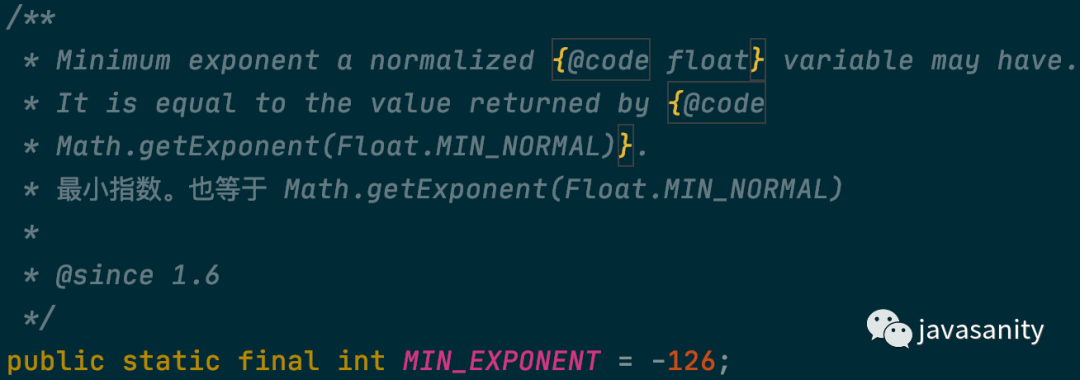
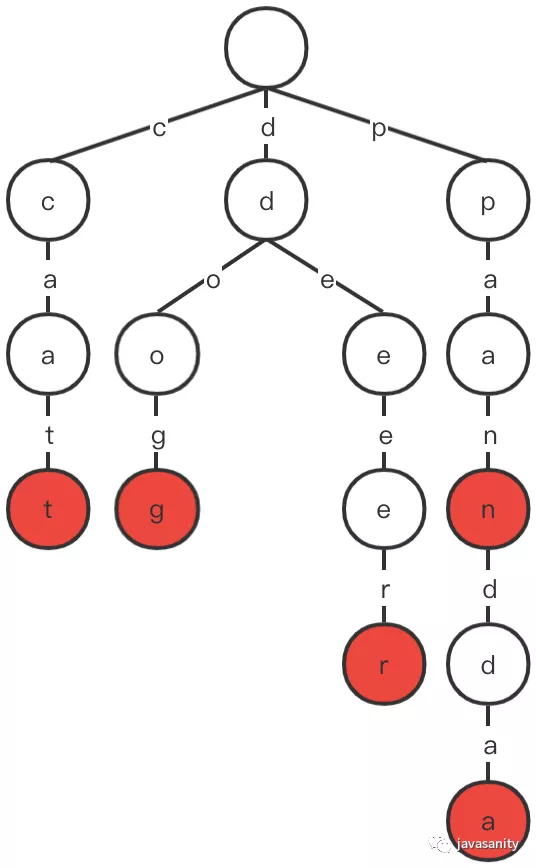
另外还有一个问题,就是有可能某个字符串是另一个字符串的前缀,这样我们就还需要知道哪些节点代表着这个字符串的结束。所以在每个 Node 中还需要再存储一个值来表示当前节点是否是某个字符串的结尾。
综上,最终的节点可以定义如下:
1 | class Node { |
结构图如下(用红色节点来表示 isEndingChar 为 true):
Trie 实现
Trie 树主要有三个操作:
- 将一个字符串插入到 Trie 树中
- 查询一个字符串是否在 Trie 树中
- 查询一个字符串在 Trie 树中是否作为某些字符串的前缀
接下来就可以动手来实现 Trie 了,这里给出两版实现。
用数组来实现
1 | /** |
用 Map 来实现
1 | import java.util.HashMap; |
更多
虽然 Trie 树如此高效,但仍然有局限性,相信大家也发现了,那就是空间问题。在某些情况下,比如重复前缀并不多时,Trie 树甚至有可能会浪费更多的内存。
这个问题又该如何解决呢?
大的思路来说,就是要在查询效率和内存之间做平衡。所以,既然要省内存,我们就牺牲一点查询的效率。
这里介绍两种思路:
- 第一种思路叫做压缩字典树(Compressed Trie),即对只有一个子节点的节点,而且此节点不是一个字符串的结束节点,将此节点与子节点合并在一起。如下图所示:
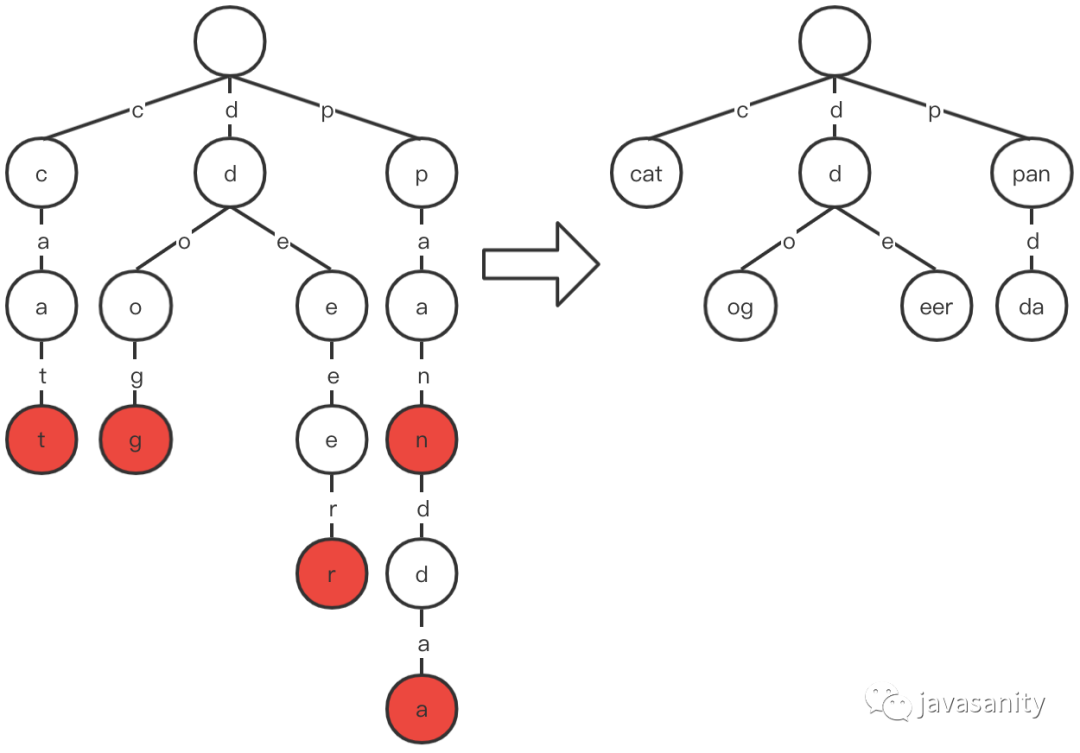
可以看到,空间明显减少,但是代价就是操作更复杂,维护成本更高,插入也会更费时。
- 第二种思路叫做三分搜索字典树(Ternary Search Trie),这种树每个节点只有三个孩子,对于任意一个节点,小于该节点字符的节点放到其左子树上,大于该节点字符的节点放到其右子树上,等于该节点字符的节点放到中间子树上。如下图所示一个三分搜索字典树的局部:
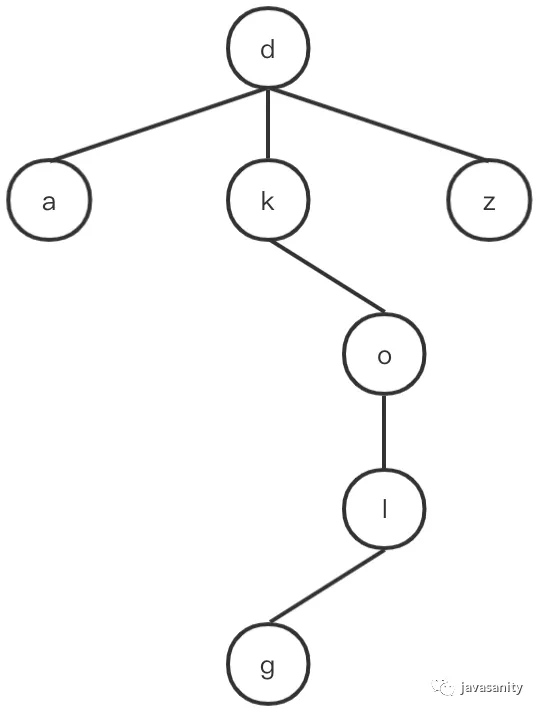
举个例子,我们要在上图中寻找 dog 这个字符串,第一个字符 d 等于 d,走中间的子树,第二个字符 o 大于 k,走右边的子树,第三个字符 g 小于 l,走左边的子树。
显然,这样时间复杂度会比字符串的长度要多,因为需要先判断当前要找的字符和当前节点字符的大小关系,再决定下一步往哪个方向走。