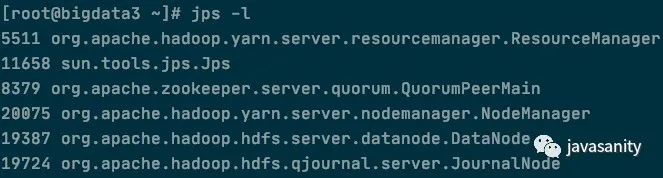
JDK 的 bin 目录下为 Java 开发人员提供了很多实用的小工具,很多场景下都会用到它们,比如:打包、部署、签名、调试、监控、运维等。本文介绍其中一款:
jstat (JVM Statistics Monitoring Tool): 虚拟机统计信息监视工具
详细信息可参考:jstat doc
功能
用于监视虚拟机各种运行状态信息的命令行工具。可以显示本地或远程虚拟机进程中的类加载、内存、垃圾收集、即时编译等运行时数据。
远程虚拟机进程
需要远程主机提供 RMI 支持,JDK 中提供了 jstatd 工具可以很方便地建立远程 RMI 服务器。
命令格式
jstat [ option vmid [interval[s|ms] [count]] ]
VMID 与 LVMID
如果是本地虚拟机进程,VMID 与 LVMID 是一致的;如果是远程虚拟机进程,那 VMID 的格式应当是:
[protocol:][//]lvmid[@hostname[:port]/servername]
interval 和 count
interval: 查询间隔。如果没有显示指定,默认单位为 ms。
count: 次数
如果省略这 2 个参数,说明只查询一次。
假设需要每 250 毫秒查询一次进程 2764 垃圾收集状况,一共查询 20 次,那命令应当是:
1 | $ jstat -gc 2764 250 20 |
option
代表用户希望查询的虚拟机信息,主要分为三类: 类加载、垃圾收集、运行期编译状况。
可以通过如下命令查看所有选项:
1 | $ jstat -options |
| 选项 | 作用 |
|---|---|
| -class | 监视类加载、卸载数量、总空间以及类装载所耗费的时间 |
| -gc | 监视 Java 堆状况,包括 Eden 区、2 个 Survivor 区、老年代、永久代等的容量,已用空间、垃圾收集时间合计等信息 |
| -gccapacity | 监视内容与 -gc 基本相同,但输出主要关注 Java 堆各个区域使用到的最大、最小空间 |
| -gcutil | 监视内容与 -gc 基本相同,但输出主要关注已使用空间占总空间的百分比 |
| -gccause | 与 -gcutil 功能一样,但是会额外输出导致上一次垃圾收集产生的原因 |
| -gcnew | 监视新生代垃圾收集状况 |
| -gcnewcapacity | 监视内容与 -gcnew 基本相同,输出主要关注使用到的最大、最小空间 |
| -gcold | 监视老年代垃圾收集状况 |
| -gcoldcapacity | 监视内容与 -gcold 基本相同,输出主要关注使用到的最大、最小空间 |
| -gcpermcapacity(x) | 输出永久代使用到的最大、最小空间 (高版本已移除) |
| -compiler | 输出即时编译器(JIT compiler,just-in-time compiler)编译过的方法、耗时等信息 |
| -printcompilation | 输出已经被即时编译的方法 |
| -gcmetacapacity | 输出 metaspace 的统计信息 |
执行样例
(旧版本可能会有 P (Permanent): 永久代)
-class
监视类加载、卸载数量、总空间以及类装载所耗费的时间。
1 | $ jstat -class 5511 |

Loaded: 加载 class 数量
Bytes: 加载占用空间
Unloaded: 卸载 class 数量
Bytes: 卸载占用空间
Time: 执行类加载和卸载操作总耗时
-gc
监视 Java 堆状况,包括 Eden 区、2 个 Survivor 区、老年代、永久代等的容量,已用空间、垃圾收集时间合计等信息。
1 | $ jstat -gc 5511 |

S0C (Survivor0 Capacity)、S1C (Survivor1 Capacity): S0 / S1 总空间 (KB)
S0U (Survivor0 Utilization)、S1U (Survivor1 Utilization): S0 / S1 已使用空间 (KB)
EC (Eden Capacity): Eden 总空间 (KB)
EU (Eden Utilization): Eden 已使用空间 (KB)
OC (Old Capacity): 老年代总空间 (KB)
OU (Old Utilization): 老年代已使用空间 (KB)
MC (Metaspace Capacity): 元数据区总空间 (KB)
MU (Metaspace Utilization): 元数据区已使用空间 (KB)
CCSC (Compressed Class Space Capacity): 压缩类空间大小 (KB)
CCSU (Compressed Class Space Utilization): 压缩类空间已使用大小 (KB)
YGC (Young GC / Minor GC): Young GC 次数
YGCT (Young GC Time): Young GC 耗时
FGC (Full GC): Full GC 次数
FGCT (Full GC Time): Full GC 耗时
GCT (GC Time): GC 总耗时
-gccapacity
监视内容与 -gc 基本相同,但输出主要关注 Java 堆各个区域使用到的最大、最小空间。
1 | $ jstat -gccapacity 5511 |

NGCMN (New Generation Capacity Min): 新生代最小容量 (KB)
NGCMX (New Generation Capacity Max): 新生代最大容量 (KB)
NGC (New Generation Capacity): 新生代总空间 (KB)
S0C (Survivor0 Capacity)、S1C (Survivor1 Capacity): S0 / S1 总空间 (KB)
EC (Eden Capacity): Eden 总空间 (KB)
OGCMN (Old Generation Capacity Min): 老年代最小容量 (KB)
OGCMX (Old Generation Capacity Max): 老年代最大容量 (KB)
OGC (Old Generation Capacity)、OC (Old Capacity): 老年代总空间 (KB)
MCMN (Metaspace Capacity Min): 元数据区最小容量 (KB)
MCMX (Metaspace Capacity Max): 元数据区最大容量 (KB)
MC (Metaspace Capacity): 元数据区总空间 (KB)
CCSMN (Compressed Class Space Min): 压缩类空间最小容量 (KB)
CCSMX (Compressed Class Space Max): 压缩类空间最大容量 (KB)
CCSC (Compressed Class Space Capacity): 压缩类空间大小 (KB)
YGC (Young GC / Minor GC): Young GC 次数
FGC (Full GC): Full GC 次数
-gcutil
监视内容与 -gc 基本相同,但输出主要关注已使用空间占总空间的百分比。
1 | $ jstat -gcutil 5511 |

S0 (Survivor0)、S1 (Survivor1): S0 / S1 使用比例
E (Eden): Eden 使用比例
O (Old): 老年代使用比例
M (Metaspace): 元数据区使用比例
CCS (Compressed Class Space): 压缩类空间使用比例
YGC (Young GC / Minor GC): Young GC 次数
YGCT (Young GC Time): Young GC 耗时
FGC (Full GC): Full GC 次数
FGCT (Full GC Time): Full GC 耗时
GCT (GC Time): GC 总耗时
-gccause
与 -gcutil 功能一样,但是会额外输出导致上一次垃圾收集产生的原因。(输出结果比 -gcutil 多了 LGCC 和 GCC)
1 | $ jstat -gccause 5511 |

S0 (Survivor0)、S1 (Survivor1): S0 / S1 使用比例
E (Eden): Eden 使用比例
O (Old): 老年代使用比例
M (Metaspace): 元数据区使用比例
CCS (Compressed Class Space): 压缩类空间使用比例
YGC (Young GC / Minor GC): Young GC 次数
YGCT (Young GC Time): Young GC 耗时
FGC (Full GC): Full GC 次数
FGCT (Full GC Time): Full GC 耗时
GCT (GC Time): GC 总耗时
LGCC (Last GC Cause): 上次 GC 原因
GCC (GC Cause): 本次 GC 原因
-gcnew
监视新生代垃圾收集状况。
1 | $ jstat -gcnew 5511 |

S0C (Survivor0 Capacity)、S1C (Survivor1 Capacity): S0 / S1 总空间 (KB)
S0U (Survivor0 Utilization)、S1U (Survivor1 Utilization): S0 / S1 已使用空间 (KB)
TT (Tenuring Threshold): 对象在新生代的存活次数
MTT (Max Tenuring Threshold): 对象在新生代存活的最大次数
DSS (Desired Survivor Size): 期望的幸存区大小 (KB)
EC (Eden Capacity): Eden 总空间 (KB)
EU (Eden Utilization): Eden 已使用空间 (KB)
YGC (Young GC / Minor GC): Young GC 次数
YGCT (Young GC Time): Young GC 耗时
-gcnewcapacity
监视内容与 -gcnew 基本相同,输出主要关注使用到的最大、最小空间。
1 | $ jstat -gcnewcapacity 5511 |

NGCMN (New Generation Capacity Min): 新生代最小容量 (KB)
NGCMX (New Generation Capacity Max): 新生代最大容量 (KB)
NGC (New Generation Capacity): 新生代总空间 (KB)
S0CMX (Survivor0 Capacity Max): S0 最大容量 (KB)
S0C (Survivor0 Capacity): S0 总空间 (KB)
S1CMX (Survivor1 Capacity Max): S1 最大容量 (KB)
S1C (Survivor1 Capacity): S1 总空间 (KB)
ECMX (Eden Capacity Max): Eden 最大容量 (KB)
EC (Eden Capacity): Eden 总空间 (KB)
YGC (Young GC / Minor GC): Young GC 次数
FGC (Full GC): Full GC 次数
-gcold
监视老年代垃圾收集状况。
1 | $ jstat -gcold 5511 |

MC (Metaspace Capacity): 元数据区总空间 (KB)
MU (Metaspace Utilization): 元数据区已使用空间 (KB)
CCSC (Compressed Class Space Capacity): 压缩类空间大小 (KB)
CCSU (Compressed Class Space Utilization): 压缩类空间已使用大小 (KB)
OC (Old Capacity): 老年代总空间 (KB)
OU (Old Utilization): 老年代已使用空间 (KB)
YGC (Young GC / Minor GC): Young GC 次数
FGC (Full GC): Full GC 次数
FGCT (Full GC Time): Full GC 耗时
GCT (GC Time): GC 总耗时
-gcoldcapacity
监视内容与 -gcold 基本相同,输出主要关注使用到的最大、最小空间。
1 | $ jstat -gcoldcapacity 5511 |

OGCMN (Old Generation Capacity Min): 老年代最小容量 (KB)
OGCMX (Old Generation Capacity Max): 老年代最大容量 (KB)
OGC (Old Generation Capacity)、OC (Old Capacity): 老年代总空间 (KB)
OC (Old Capacity): 老年代总空间 (KB)
YGC (Young GC / Minor GC): Young GC 次数
FGC (Full GC): Full GC 次数
FGCT (Full GC Time): Full GC 耗时
GCT (GC Time): GC 总耗时
-gcpermcapacity (x)
输出永久代使用到的最大、最小空间。(高版本已移除)
1 | $ jstat -gcpermcapacity 5511 |
会提示:Unknown option: -gcpermcapacity
-compiler
输出即时编译器(JIT compiler,just-in-time compiler)编译过的方法、耗时等信息。
1 | $ jstat -compiler 5511 |

Compiled: 编译任务数
Failed: 失败的编译任务数
Invalid: 无效的编译任务数
Time: 编译花费时间
FailedType: 上次编译失败的编译类型
FailedMethod: 上次编译失败的类名和方法
-printcompilation
输出已经被即时编译的方法。
1 | $ jstat -printcompilation 5511 |

Compiled: 最近编译方法的数量
Size: 最近编译方法的字节码数量
Type: 最近编译方法的编译类型
Method: 标识最近编译方法的类名和方法名。这两个字段的格式与 HotSpot - XX:+PrintComplation 选项一致
-gcmetacapacity
输出 metaspace 的统计信息。
1 | $ jstat -gcmetacapacity 5511 |

MCMN (Metaspace Capacity Min): 元数据区最小容量 (KB)
MCMX (Metaspace Capacity Max): 元数据区最大容量 (KB)
MC (Metaspace Capacity): 元数据区总空间 (KB)
CCSMN (Compressed Class Space Min): 压缩类空间最小容量 (KB)
CCSMX (Compressed Class Space Max): 压缩类空间最大容量 (KB)
CCSC (Compressed Class Space Capacity): 压缩类空间大小 (KB)
YGC (Young GC / Minor GC): Young GC 次数
FGC (Full GC): Full GC 次数
FGCT (Full GC Time): Full GC 耗时
GCT (GC Time): GC 总耗时