/** * Initialize the data structure. */ publicTrie(){ root = new Node(); }
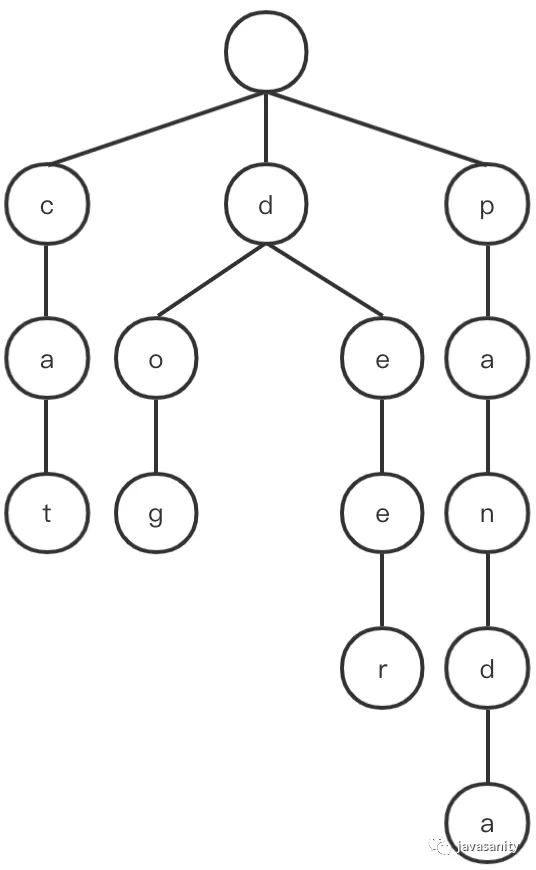
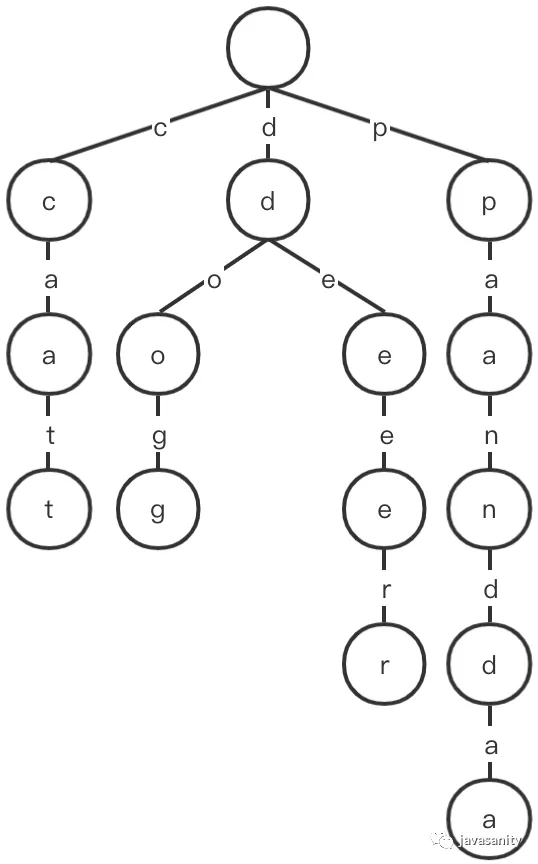
/** * Inserts a word into the trie. */ publicvoidinsert(String word){ Node cur = root; for (int i = 0; i < word.length(); i++) { char c = word.charAt(i); int index = c - 'a'; if (cur.next[index] == null) { cur.next[index] = new Node(); } cur = cur.next[index]; } cur.isEndingChar = true; }
/** * search a prefix or whole key in trie and returns the node where search ends */ private Node searchPrefix(String word){ Node cur = root; for (int i = 0; i < word.length(); i++) { char c = word.charAt(i); int index = c - 'a'; if (cur.next[index] == null) { returnnull; } cur = cur.next[index]; } return cur; }
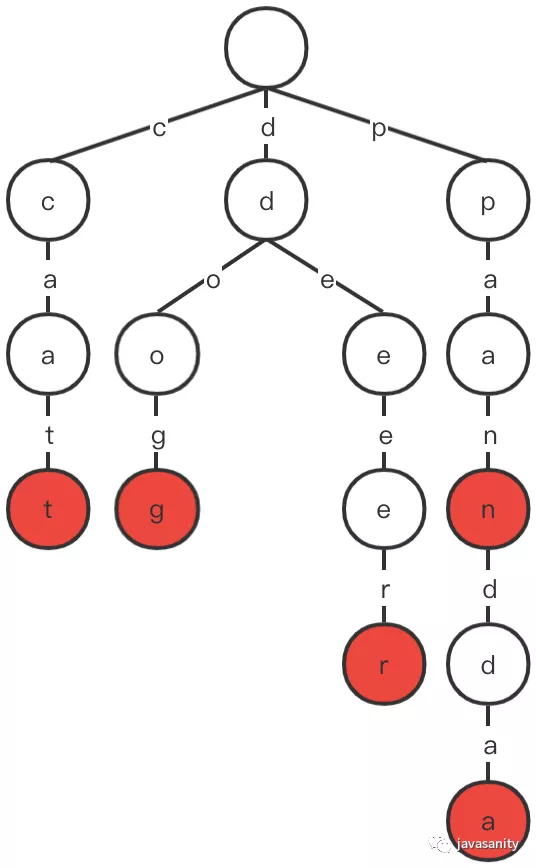
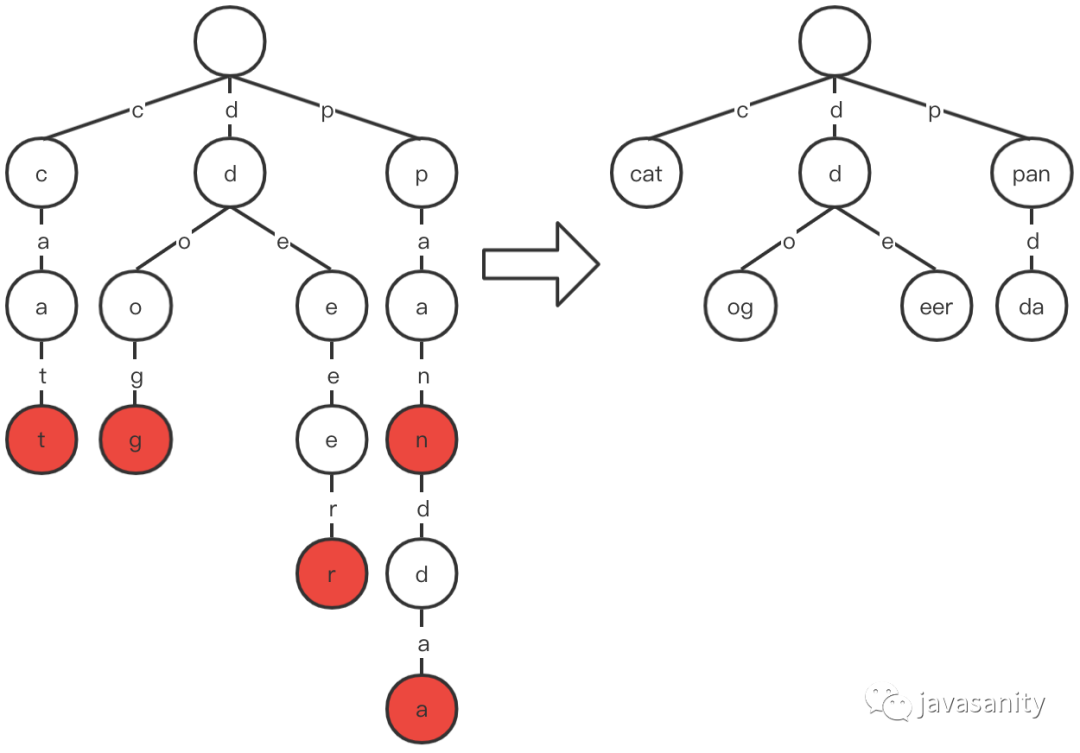
/** * Returns if the word is in the trie. */ publicbooleansearch(String word){ Node node = searchPrefix(word); return node != null && node.isEndingChar; }
/** * Returns if there is any word in the trie that starts with the given prefix. */ publicbooleanstartsWith(String word){ Node node = searchPrefix(word); return node != null; }
privatestaticclassNode{
/** * 该节点是否是字符串的结尾 */ publicboolean isEndingChar;
/** * 指向后续节点的指针 */ public Node[] next;
publicNode(boolean isEndingChar){ this.isEndingChar = isEndingChar; next = new Node[26]; }
/** * Initialize the data structure. */ publicTrie(){ root = new Node(); }
/** * Inserts a word into the trie. */ publicvoidinsert(String word){ Node cur = root; for (int i = 0; i < word.length(); i++) { char c = word.charAt(i); if (!cur.next.containsKey(c)) { cur.next.put(c, new Node()); } cur = cur.next.get(c); } cur.isEndingChar = true; }
/** * search a prefix or whole key in trie and returns the node where search ends */ private Node searchPrefix(String word){ Node cur = root; for (int i = 0; i < word.length(); i++) { char c = word.charAt(i); if (!cur.next.containsKey(c)) { returnnull; } cur = cur.next.get(c); } return cur; }
/** * Returns if the word is in the trie. */ publicbooleansearch(String word){ Node node = searchPrefix(word); return node != null && node.isEndingChar; }
/** * Returns if there is any word in the trie that starts with the given prefix. */ publicbooleanstartsWith(String word){ Node node = searchPrefix(word); return node != null; }
privatestaticclassNode{
/** * 该节点是否是字符串的结尾 */ publicboolean isEndingChar;
/** * 指向后续节点的指针 */ public Map<Character, Node> next;
publicNode(boolean isEndingChar){ this.isEndingChar = isEndingChar; next = new HashMap<>(); }