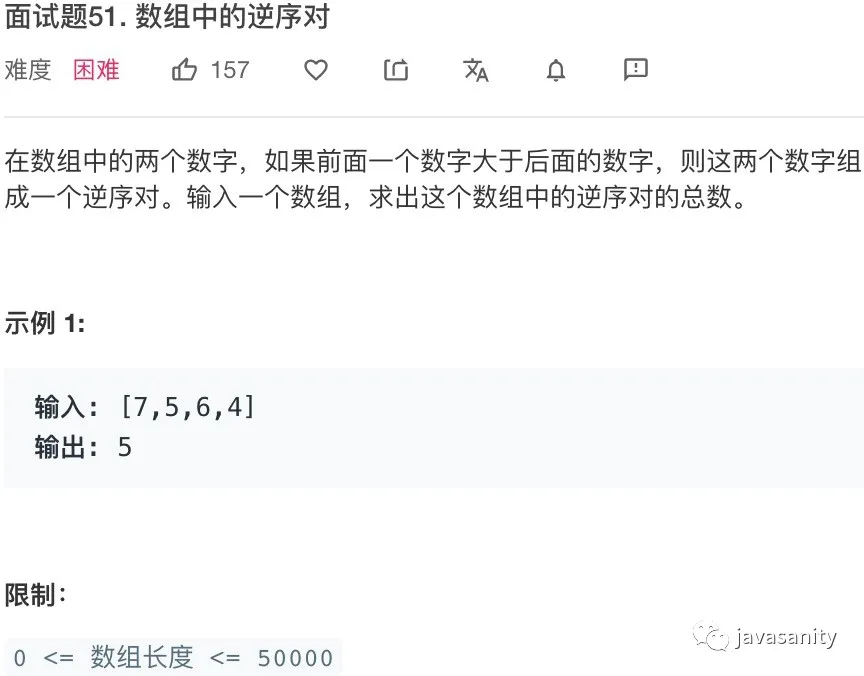
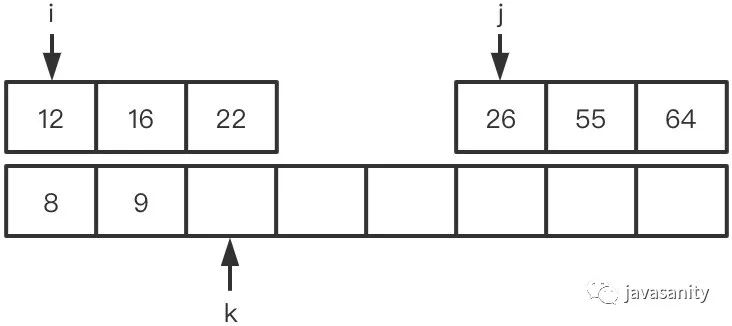
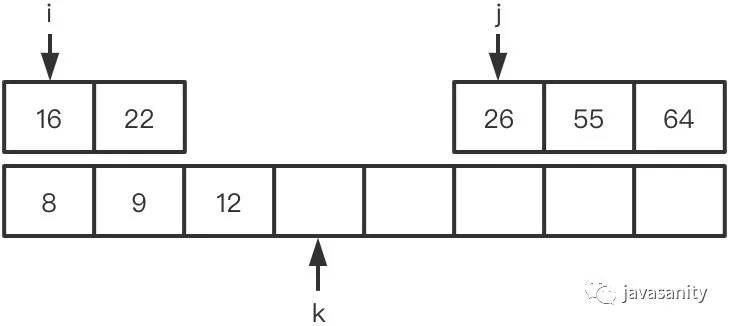
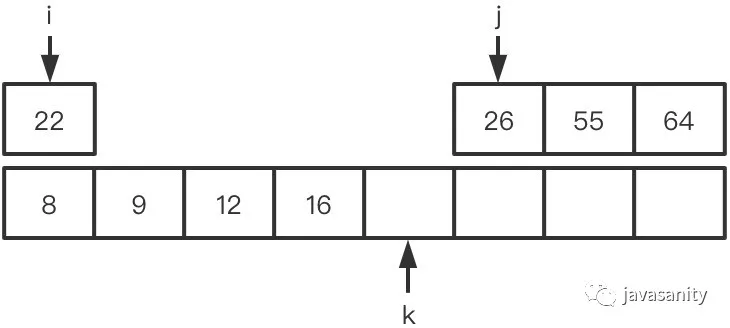
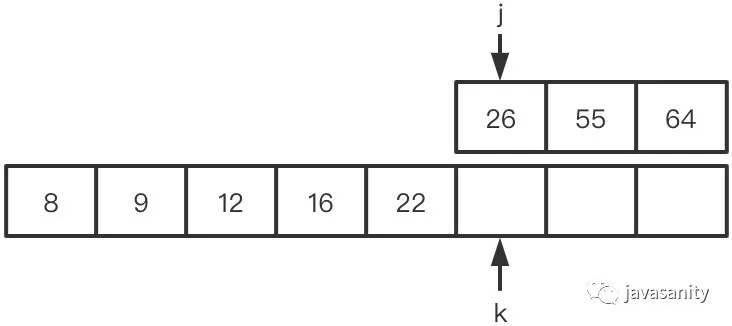
/** * 采用归并排序自底向上写法,具体可见归并排序文章 * 当然也可以用自顶向下递归的方式来写,都是一样的,这部分其实也不是解题的重点 */ publicintreversePairs(int[] nums){ // ret 为逆序对总数 int ret = 0, n = nums.length; if (n < 2) { return0; } for (int i = 1; i < n; i *= 2) { for (int j = 0; j < n - i; j += 2 * i) { int mid = j + i - 1; if (nums[mid] > nums[j + i]) { ret += reversePairsHelper(nums, j, mid, Math.min(mid + i, n - 1)); } } } return ret; }
/** * “merge”考虑左数组 */ privateintreversePairsHelper(int[] nums, int left, int mid, int right){ int[] temp = newint[right - left + 1]; int i = left, j = mid + 1, k = 0, ret = 0; while (i <= mid && j <= right) { if (nums[i] <= nums[j]) { temp[k++] = nums[i++]; } else { // 重点 ret += mid - i + 1; temp[k++] = nums[j++]; } } while (i <= mid) { temp[k++] = nums[i++]; } while (j <= right) { temp[k++] = nums[j++]; } System.arraycopy(temp, 0, nums, left, temp.length); return ret; }
在右边的有序数组上思考
要比在左数组思考多考虑一点点,不过也比较简单。
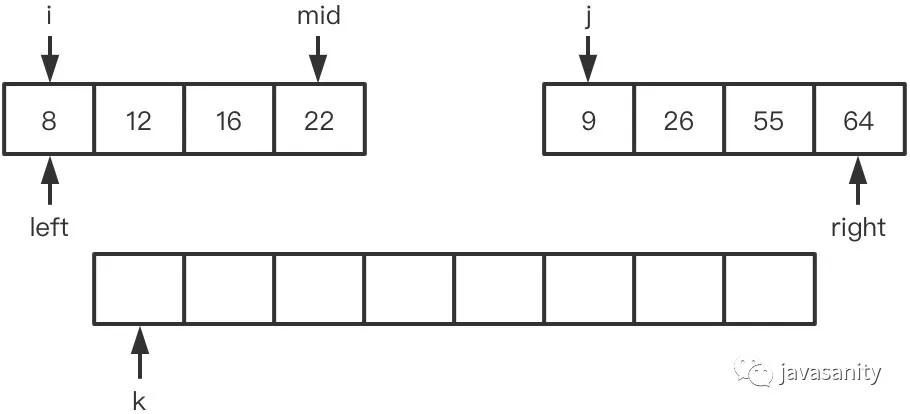
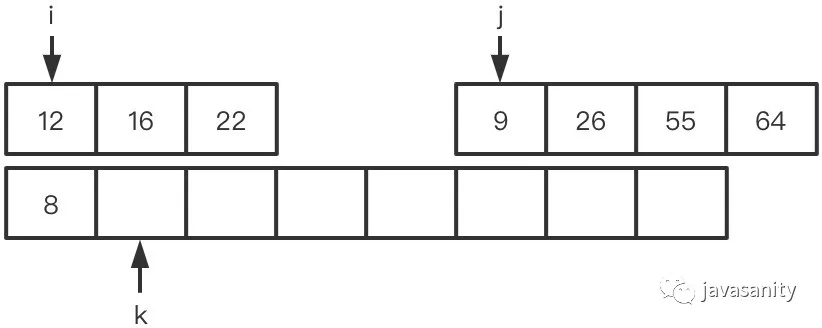
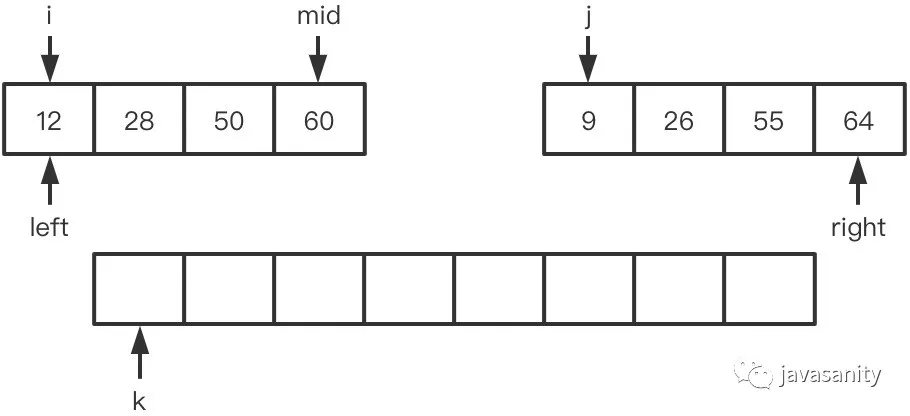
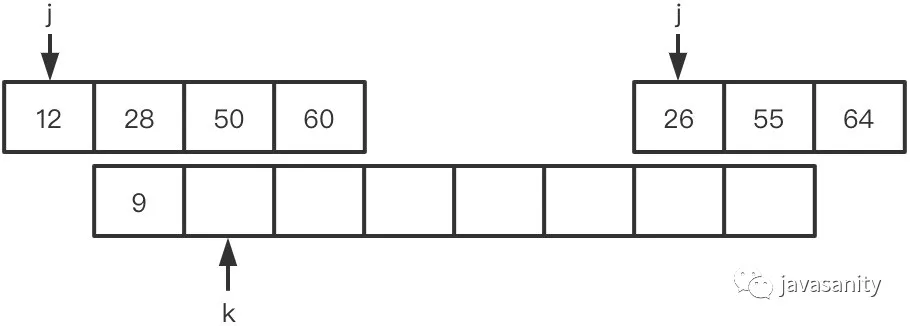
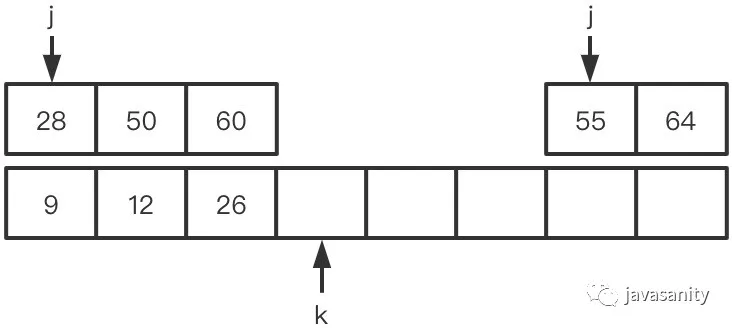
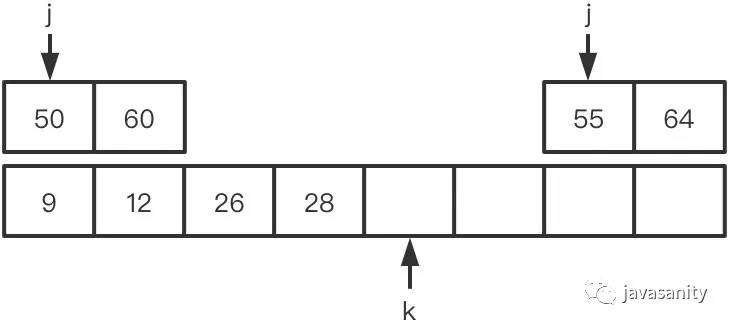
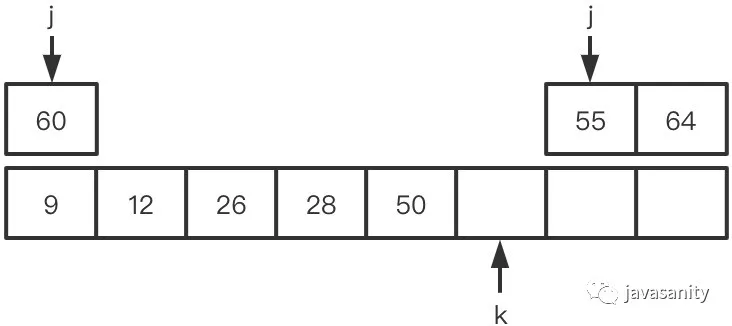
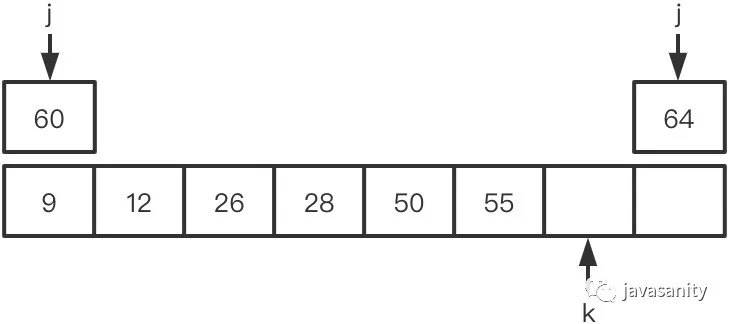
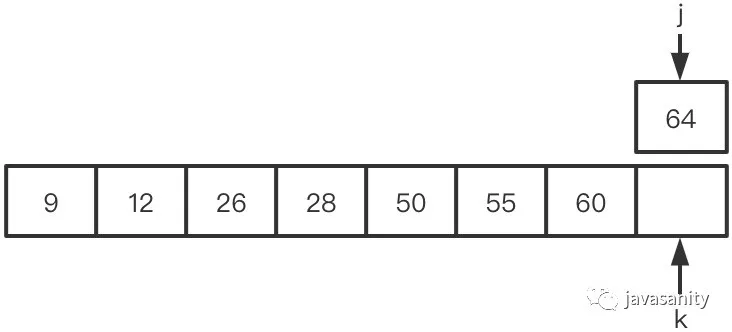
假定待 merge 数组如下,记逆序对总数为 ret: (1)12 > 9,ret 不变,此时 ret = 0 (2)12 < 26,12 和右数组 26 之前的所有数构成逆序对,此时 ret = 1 (3)28 > 26,ret 不变,此时 ret = 1 (4)28 < 55,28 和右数组 55 之前的所有数构成逆序对,此时 ret = 3 (5)50 < 55,50 和右数组 55 之前的所有数构成逆序对,此时 ret = 5 (6)60 > 55,ret 不变,此时 ret = 5 (7)60 < 64,60 和右数组 64 之前的所有数构成逆序对,此时 ret = 8 (8)左数组遍历完,右数组剩下的元素入辅助数组。因为此时右数组剩下的值比原左数组的所有值都大,不会构成逆序对,所以这一轮 merge 的最终 ret = 8
明白了这一点,那就好做了。我们可以从后往前遍历 a,当遍历到 a[i] 时,把对应的新数组中 i 位置的值自增 1,然后再计算 i - 1 的前缀和,记到 ret 中。当 a 遍历完成后,ret 即为逆序对总数。
为什么可以这么做呢?因为我们在遍历 a 的过程中,把 a 分成了两部分,一部分遍历过(在新数组中),另一部分待遍历(不在新数组中)。那么对于 a[i] 来说,我们求到的 i - 1 位置的前缀和,就是遍历过的元素中比 a[i] 小的元素的总和,而这些元素在 a 中本来就是排在 a[i] 后面的,但它们的值是比 a[i] 小的,所以这就形成了一个逆序对。
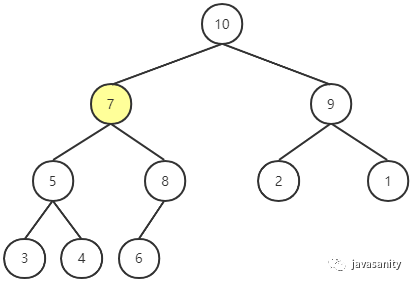
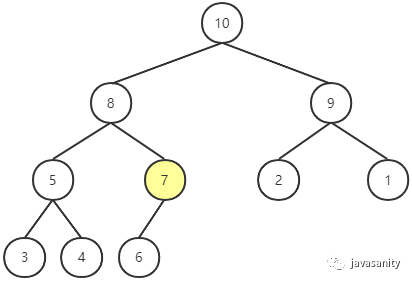
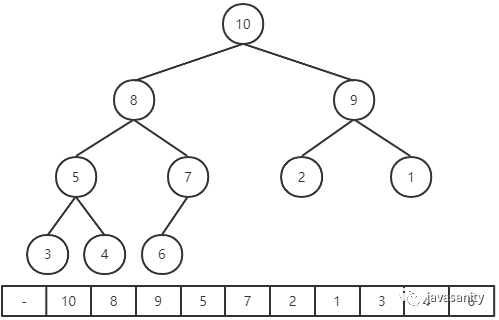
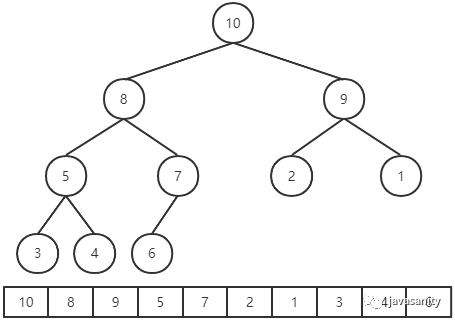
privatevoidshiftUp(int i){ // i 父节点的索引 int ip; // i 不是根节点 && i 的父节点的值 < i 节点的值 while (i > 0 && this.data[ip = (i - 1) / 2] < this.data[i]) { swap(i, ip); i = ip; } }
// 优化 shiftUp,不一直swap privatevoidshiftUp2(int i){ int e = this.data[i]; // i 父节点的索引 int ip; // i 不是根节点 && i 的父节点的值 < i 节点的值 while (i > 0 && this.data[ip = (i - 1) / 2] < e) { this.data[ip] = this.data[i]; i = ip; } this.data[i] = e; }
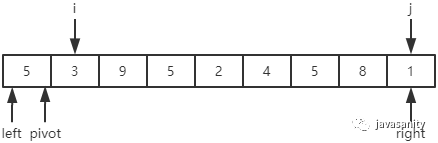
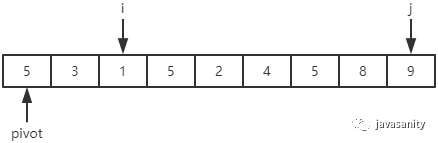
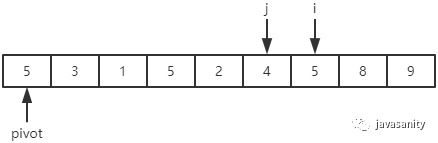
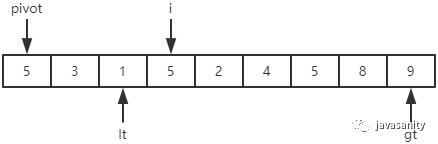
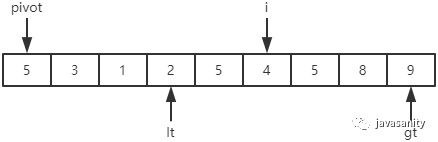
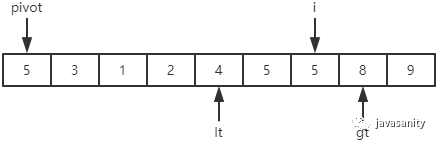
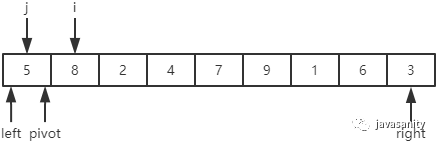
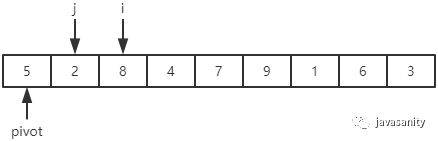
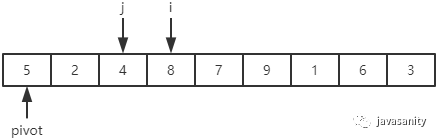
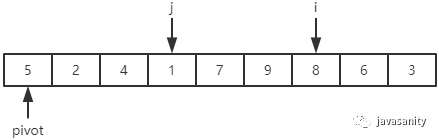
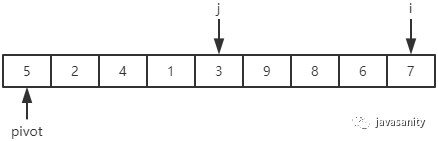
先从 i 开始向后扫描(或者,也可以先从 j 开始向前扫描),如果还没有遍历到 right 位置且当前值小于基准值,则不处理,继续查看下一个元素,直到找到一个值大于等于基准值; 这时从 j 开始向前扫描,如果还没有遍历到 left + 1 位置且当前值大于基准值,则不处理,继续查看下一个元素,直到找到一个值小于等于基准值; 此时,如果 i <= j,则交换 i 和 j 位置的值,之后 i 和 j 再分别指向下一个元素;否则跳出循环; 跳出循环后,现在应该把基准值放到合适的位置。那么这个位置是 i 还是 j 呢?分析一下:此时 i 的位置,是从前往后第一个大于等于基准值的元素;此时 j 的位置,是从后往前第一个(也就是从前往后最后一个)小于等于基准值的元素;而基准值是处在小于等于基准值的这一端,所以要将 pivot 和 j 位置的值进行交换即可。
/** * 递归使用双路快排排序 * @param data 待排序的数组 * @param left 起始位置 * @param right 结束位置 */ privatestaticvoidquickSortHelper(int[] data, int left, int right){ // 优化1:对于小规模数组(这里指定为16个元素), 使用插入排序 if(right - left <= 15){ insertSort(data, left, right); return; } int pivot = partition(data, left, right); // 递归排序基准数左部分 quickSortHelper(data, left, pivot - 1); // 递归排序基准数右部分 quickSortHelper(data, pivot + 1, right); }
/** * 对数组 [left, right] 部分进行 partition 操作,双路 * @param data 待排序的数组 * @param left 起始位置 * @param right 结束位置 * @return 返回基准值位置,保证 data[left...pivot - 1] < data[pivot]; data[pivot + 1...right] > data[pivot] */ privatestaticintpartition(int[] data, int left, int right){ // 优化2:随机在 data[left...right] 范围中, 选择一个位置作为基准值 int randomIndex = (int) (Math.random() * (right - left + 1)) + left; int temp = data[left]; data[left] = data[randomIndex]; data[randomIndex] = temp; // pivot,i,j 的定义在上边已经介绍 int pivot = data[left], i = left + 1, j = right; while (true) { while (i <= right && data[i] < pivot) { i++; } while (j >= left + 1 && data[j] > pivot) { j--; } if (i > j) { break; } // swap i and j temp = data[i]; data[i] = data[j]; data[j] = temp; i ++; j --; } // swap left and j data[left] = data[j]; data[j] = pivot; return j; }
/** * 为了方便大家观看,这个插入排序的代码是直接从上一篇中拿过来的 * 对data[l...r]的区间使用插入排序 * @param data 待排序数组 * @param l 起始index,代表left * @param r 结尾index,代表right */ privatestaticvoidinsertSort(int[] data, int l, int r){ for( int i = l + 1 ; i <= r ; i ++ ){ int e = data[i]; int j = i; for (; j > l && data[j-1] > e; j--) { data[j] = data[j - 1]; } data[j] = e; } }
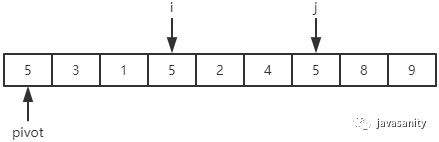
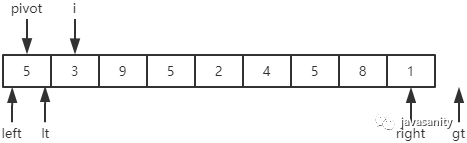
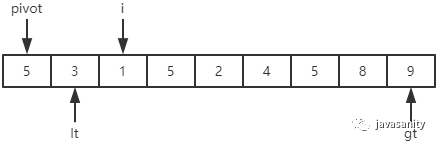
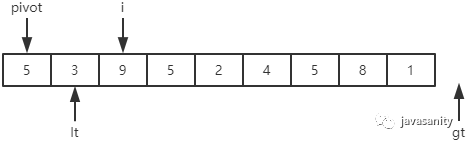
/** * 递归使用三路快排排序 * 直接包含了对数组 [left, right] 部分进行 partition 操作的代码 * @param data 待排序的数组 * @param left 起始位置 * @param right 结束位置 */ privatestaticvoidquickSortHelper(int[] data, int left, int right){ // 优化1:对于小规模数组(这里指定为16个元素), 使用插入排序 if (right - left <= 15) { insertSort(data, left, right); return; } /* partition start */ // 优化2:随机在 data[left...right] 范围中, 选择一个位置作为基准值 int randomIndex = (int) (Math.random() * (right - left + 1)) + left; int temp = data[left]; data[left] = data[randomIndex]; data[randomIndex] = temp; // pivot,i,lt,gt 的定义在上边已经介绍 int pivot = data[left], lt = left, gt = right + 1, i = left + 1; while (i < gt) { if (data[i] < pivot) { // swap i and lt + 1 temp = data[i]; data[i] = data[lt + 1]; data[lt + 1] = temp; i ++; lt ++; } elseif (data[i] > pivot) { // swap i and gt - 1 temp = data[i]; data[i] = data[gt - 1]; data[gt - 1] = temp; gt --; } else { // if (data[i] == pivot) i ++; } } // swap left and lt data[left] = data[lt]; data[lt] = pivot; /* partition end */ // 递归排序数组左部分 quickSortHelper(data, left, lt - 1); // 递归排序数组右部分 quickSortHelper(data, gt, right); }
/** * 为了方便大家观看,这个插入排序的代码是直接从上一篇中拿过来的 * 对data[l...r]的区间使用插入排序 * @param data 待排序数组 * @param l 起始index,代表left * @param r 结尾index,代表right */ privatestaticvoidinsertSort(int[] data, int l, int r){ for( int i = l + 1 ; i <= r ; i ++ ){ int e = data[i]; int j = i; for (; j > l && data[j-1] > e; j--) { data[j] = data[j - 1]; } data[j] = e; } }
/** * 递归使用单路快排排序 * @param data 待排序的数组 * @param left 起始位置 * @param right 结束位置 */ privatestaticvoidquickSortHelper(int[] data, int left, int right){ // 优化1:对于小规模数组(这里指定为16个元素), 使用插入排序 if(right - left <= 15){ insertSort(data, left, right); return; } int pivot = partition(data, left, right); // 递归排序基准数左部分 quickSortHelper(data, left, pivot - 1); // 递归排序基准数右部分 quickSortHelper(data, pivot + 1, right); }
/** * 对数组 [left, right] 部分进行 partition 操作,从左往右单路 * @param data 待排序的数组 * @param left 起始位置 * @param right 结束位置 * @return 返回基准值位置,保证 data[left...pivot - 1] < data[pivot]; data[pivot + 1...right] > data[pivot] */ privatestaticintpartition(int[] data, int left, int right){ // 优化2:随机在 data[left...right] 范围中, 选择一个位置作为基准值 int randomIndex = (int) (Math.random() * (right - left + 1)) + left; int temp = data[left]; data[left] = data[randomIndex]; data[randomIndex] = temp; // 下面逻辑完全不变 // pivot,i,j的定义在上边已经介绍 int pivot = data[left], j = left; for (int i = left + 1 ; i <= right; i ++) { if (data[i] < pivot) { j++; // swap i and j + 1 temp = data[j]; data[j] = data[i]; data[i] = temp; } } // swap left and j data[left] = data[j]; data[j] = pivot; return j; }
/** * 为了方便大家观看,这个插入排序的代码是直接从上一篇中拿过来的 * 对data[l...r]的区间使用插入排序 * @param data 待排序数组 * @param l 起始index,代表left * @param r 结尾index,代表right */ privatestaticvoidinsertSort(int[] data, int l, int r){ for( int i = l + 1 ; i <= r ; i ++ ){ int e = data[i]; int j = i; for (; j > l && data[j-1] > e; j--) { data[j] = data[j - 1]; } data[j] = e; } }