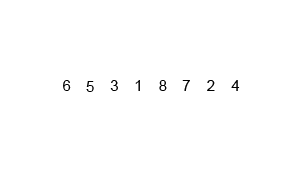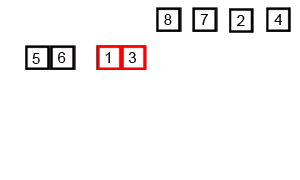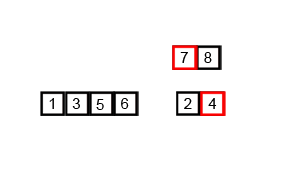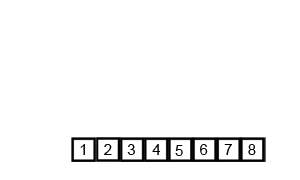归并排序(merge sort)是1945年由科学家约翰·冯·诺伊曼(John von Neumann)首次提出的,它是分治法的一个非常典型的应用。
当然,它也是面试中算法的一个高频考察点。(一说到面试,你是不是都有动力看下去了呢)
归并排序思想 首先简单介绍一下分治法(Divide and Conquer)。在计算机科学中,分治法是基于多项分支递归的一种很重要的算法范式。在每一层递归上一般有三个步骤:分解,解决,合并。分治的字面意思是“分而治之”,就是把一个复杂的问题分成多个相同或相似的子问题,最终子问题可以简单的直接求解,然后合并子问题的解即可得到原问题的解。这个思想也是很多高效算法的基础。
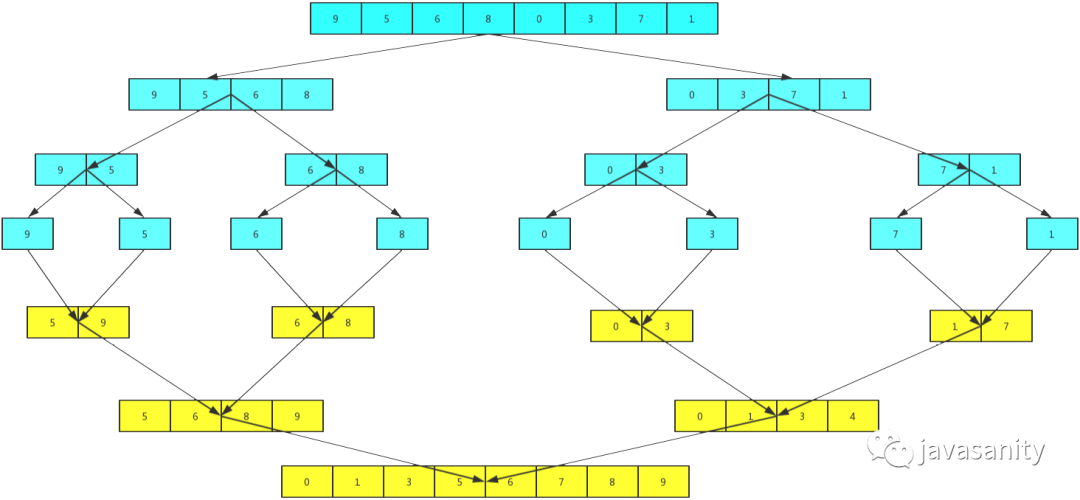
接下来就演示一下归并排序的整个过程吧。这次就不用文字来描述了,直接用两张图,因为图更直观些,相信看完你就能明白。
从demo中,我们可以看到,归并排序算法整体上可以分为两个部分:
分组:递归地把当前数组分割成两部分,直到不可再分割为止,此时,每个数组中只有一个元素;
归并(merge):将两个已经有序的数组合并成一个有序的数组,最终,就会得到一个排好序的数组。
可以看到 merge 操作的代码写的怎么样基本上就决定了归并算法的好坏,那么应该怎么写呢?大家可以先思考一下。
这个问题是一个典型的“看起来比较简单,真正操作起来会发现其实并没有那么简单”的问题。merge 的过程通常不能直接在原数组上通过交换位置来完成,而是需要开辟一个同样大小的临时空间来辅助完成这个过程。
当使用这个临时空间后,归并的过程就变得比较容易。但这也算是归并排序的一个缺点,即多使用了O(n)的存储空间。不过在现代的计算机中,时间效率要比空间效率重要的多。因为无论是内存也好,或者硬盘也好,都变得越来越廉价,可以存储的数据规模也越来越大,因此,如果数据存储空间不是算法过程中的瓶颈,我们设计的算法通常优先考虑时间复杂度。
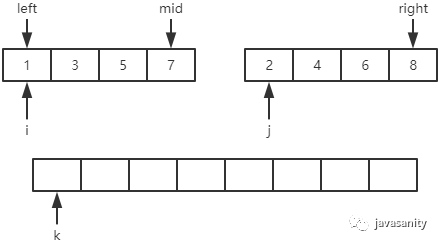
归并排序代码 在 merge 的代码实现上,主要思路是用三个索引来在数组内进行追踪。如下图:
其实定义上图中的这些变量非常重要,举个例子,假如上图中定义的 mid 指向的是 2,那么写出来的代码就是完全不一样的。
在真正写代码之前,还要再啰嗦一句。其实归并排序的代码可以有两种写法:“Top-down”和“Bottom-up”,或者也可以称为“自顶向下”和“自底向上”,或者也可以称为“递归法”和“非递归法”(迭代法)。不要慌,下面都会给出代码示例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public void mergeSort (int [] data) sort(data, 0 , data.length - 1 ); } private void sort (int [] data, int left, int right) if (left >= right) { return ; } int mid = left + ((right - left) >> 1 ); sort(data, left, mid); sort(data, mid + 1 , right); merge(data, left, mid, right); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public void mergeSort (int [] data) int n = data.length; for (int i = 1 ; i < n; i *= 2 ) { for (int j = 0 ; j < n - i; j += 2 * i) { merge(data, j, j + i - 1 , Math.min(j + 2 * i - 1 , n - 1 )); } } }
因为归并排序的两种写法的 merge 部分是一样的,所以这里单独给出 merge 方法的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 private static void merge (int [] data, int left, int mid, int right) int [] temp = new int [right - left + 1 ]; int i = left, j = mid + 1 , k = 0 ; while (i <= mid && j <= right) { temp[k++] = data[i] <= data[j] ? data[i++] : data[j++]; } while (i <= mid) { temp[k++] = data[i++]; } while (j <= right) { temp[k++] = data[j++]; } System.arraycopy(temp, 0 , data, left, temp.length); }
为了开拓大家的思路,下面再给出一种 merge 方法的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 private static void merge (int [] data, int left, int mid, int right) int [] temp = Arrays.copyOfRange(data, left, right + 1 ); int i = left, j = mid + 1 ; for (int k = left ; k <= right; k ++) { if (i > mid) { data[k] = temp[j - left]; j ++; } else if (j > right) { data[k] = temp[i - left]; i ++; } else if (temp[i - left] < temp[j - left]) { data[k] = temp[i - left]; i ++; } else { data[k] = temp[j - left]; j ++; } } }
归并排序优化 这里要讲两个小的优化点:
前面我们在分完组后直接进行 merge 操作,其实我们忽略了一种情况,那就是在分完组后 merge 之前,有可能两个数组已经就是有序的了,这时候就没必要再进行 merge 操作了。
具体在代码优化实现上,可以在 merge 之前加一个判断,判断如果 data[mid] > data[mid+1],才进行 merge 操作。如果要处理的数据场景有可能会出现近乎有序的情况,我们可以加上这个优化。
第二个优化点要用到我们前面聊插入排序时的知识,在插入排序的最后,我们说到插入排序可以在更加复杂的排序算法中作为一个子过程来优化,便可以用在这里。
具体在代码优化实现上,可以在递归到数据量比较小时,转而使用插入排序提高性能。因为当数据量比较小的时候,插入排序会比归并排序快一些(此时整个数组近乎有序的概率也会比较大)。
不过,讲道理,虽然这两个优化点对归并排序的时间复杂度并没有影响,但是确实会让程序运行快一些。
归并排序优化代码 首先,需要对插入排序的代码进行一定的改写,要支持指定范围的插入排序,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 private static void insertSort (int [] data, int l, int r) for ( int i = l + 1 ; i <= r ; i ++ ){ int e = data[i]; int j = i; for (; j > l && data[j-1 ] > e; j--) { data[j] = data[j - 1 ]; } data[j] = e; } }
当然,归并排序的两种写法都可以用到上面提到的两个优化点(merge 代码同上)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public void mergeSort (int [] data) sort(data, 0 , data.length - 1 ); } private static void sort (int [] data, int l, int r) if (r - l <= 15 ) { insertSort(data, l, r); return ; } int mid = l + ((r - l) >> 1 ); sort(data, l, mid); sort(data, mid + 1 , r); if (data[mid] > data[mid+1 ]) { merge(data, l, mid, r); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public void mergeSort (int [] data) int n = data.length; for (int i = 0 ; i < n; i += 16 ) { insertSort(data, i, Math.min(i + 15 , n - 1 )); } for (int i = 16 ; i < n; i *= 2 ) { for (int j = 0 ; j < n - i; j += 2 * i) { if (data[j + i - 1 ] > data[j + i]) { merge(data, j, j + i - 1 , Math.min(j + 2 * i - 1 , n - 1 )); } } } }
复杂度和稳定性分析 大家可能都了解过,归并排序的时间复杂度为 O(n * logn),那么它是怎么计算的呢?大致如下:
首先计算分组后的层数。会发现:如果数组有 n 个元素,那么层数就为 logn。如果 n 不是 2 的次方也没有关系,因为此时 logn 的结果是个浮点数,上取整即可。
接下来要分析 merge 的时间复杂度。会发现:虽然我们把它分成了不同的部分,但是每一层要处理的元素个数都是一样的。那么如果整个过程能够用 O(n) 的时间复杂度来解决,那么我们代码的时间复杂度就为 O(n * logn) 级别。而我们实现的 merge 操作时间复杂度就是 O(n)。
时间复杂度
最优时间复杂度:O(n * logn)
最坏时间复杂度:O(n * logn)
平均时间复杂度:O(n * logn)
空间复杂度:O(n)
前面已经分析过了,需要开辟临时空间来辅助完成 merge 过程。
归并排序是一种稳定排序。
凑字数 所谓慢工出细活,这篇文章写了两天,如果你看到这里了,能告诉我这篇文章对得起“通篇都是干货”这句话吗。